Das Institut für Informationsverarbeitung (TNT) verfügt über langjährige Expertise auf dem Gebiet der Audiosignalverarbeitung und entwickelt eine Vielzahl innovativer Algorithmen für unterschiedlichste Anwendungsbereiche. Dazu zählen unter anderem Verfahren zur Datenkompression von Audiosignalen sowie Methoden zur automatisierten Klassifikation akustischer Inhalte. Ein weiteres Forschungsprojekt befasst sich mit Algorithmen zur Lokalisierung akustischer Ereignisse sowie Verfahren zur Schätzung von Impulsantworten in Festkörpern. Darüber hinaus forschen wir an der Automatiserung der Analyse des frühkindlichen Spracherwerbs mittels Spontansprachproben und automatischer Spracherkeunnung zur Identifikation eines möglichen Sprachförderbedarfs. Dieses Exposé gibt Ihnen einen Einblick in ausgewählte aktuelle Forschungsprojekte unseres Instituts.
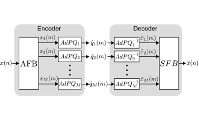
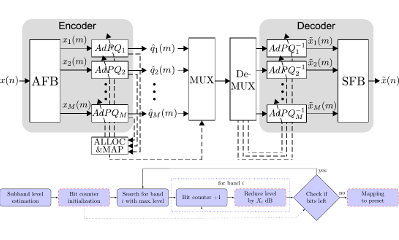
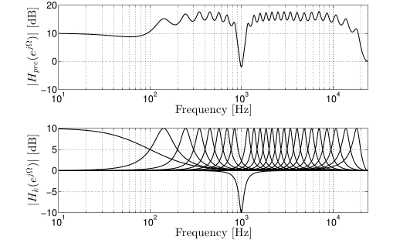
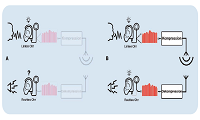
Bei Liveanwendungen wie Konzerten oder Übertragungen über das Internet ist die von einem Kodierungsverfahren hinzugefügte Verzögerung ein Problem. Die am TNT entwickelte Technik ermöglicht nahezu verzögerungsfreie Datenratenreduktion unter Erhaltung hoher Audioqualität.
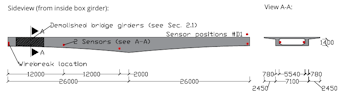
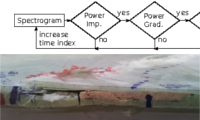
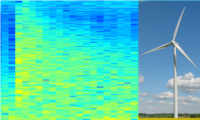
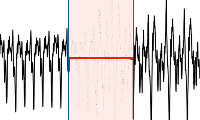
Das am TNT entworfene Verfahren erkennt Rotorblattschäden mit deutlich weniger Sensoren als vergleichbare Methoden. Dazu werden Verfahren der Audioklassifikation eingesetzt welcher in Luftschallsignalen Schäden auch bei Nebengeräuschen erkennt.
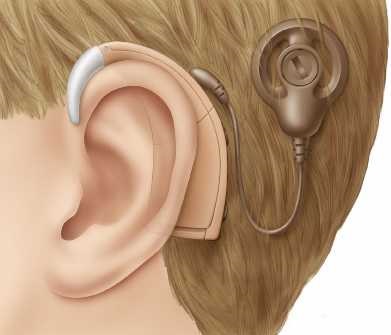
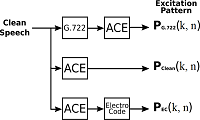
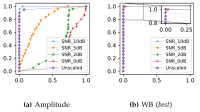
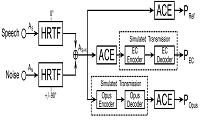
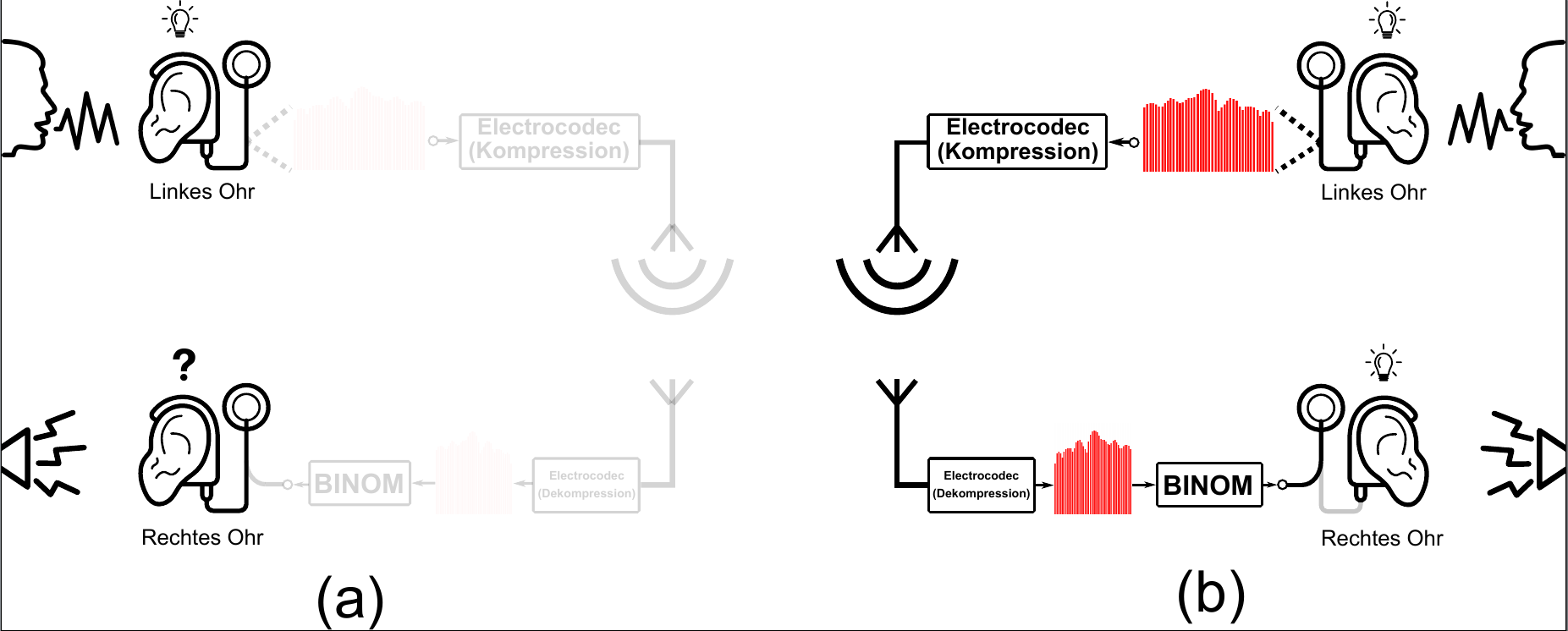
Für Träger der Hörhilfen der Cochlea-Implantate ist die Sprachverständlichkeit bei Umgebungsgeräuschen schwierig. Die am TNT entwickelten Kompressionsverfahren für Erregungsmuster ermöglichen den Einsatz binauraler Verarbeitungsstrategien. Damit ist es möglich die Sprachverständlichkeit zu erhöhen.
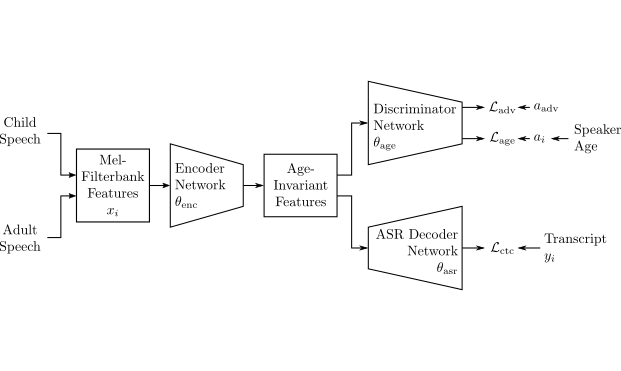
Ein erfolgreicher Spracherwerb bildet die Grundlage für gesellschaftliche Teilhabe, schulischen Bildungserfolg sowie langfristige berufliche Perspektiven. Im Kontext zunehmender gesellschaftlicher Herausforderungen – insbesondere Fachkräftemangel im Bildungs- und Therapiebereich sowie unzureichend standardisierte Diagnoseverfahren – bietet der Einsatz KI-basierter Automatisierungstechnologien ein erhebliches Innovationspotenzial zur Identifikation sprachlichen Förderbedarfs. Ein zentraler Bestandteil unseres Ansatzes ist die automatische Transkription kindlicher Spontansprachproben, welche als Grundlage für eine weiterführende Analyse mündlicher (z. B. Lexikon, morpho-syntaktische Strukturen, artikulatorische Merkmale) sowie schriftsprachlicher Kompetenzen (z. B. Lesegeschwindigkeit, -genauigkeit und -verständnis) dient. In unserer Systemarchitektur kommen aktuelle state-of-the-art Modelle aus den Bereichen Speaker Diarization, Automatic Speech Recognition und linguistischer Analyse zum Einsatz. Wir adaptieren diese Modelle domänenspezifisch und entwicklen sie kontinuierlich weiter, um eine hohe Robustheit, Genauigkeit und Interpretierbarkeit im diagnostischen Kontext sicherzustellen.
Irrelevanz reduzierende Kodierung, Klassifikationsverfahren, Künstliche Neuronale Netze, Verlustlose Kodierungsverfahren, Audio Feature Entwurf, Adaptive Vektorquantisierung, Context-Adaptive Binary Arithmetic Coding,Time Difference of Arrival Localization, Head-related transfer function