Human faces and facial expressions differ greatly between individuals. All parts of faces vary between individuals, especially between expressions of the same person. Separating inter-person changes from inter-expression changes thus poses a challenging problem for computers. On the other hand, human observers can easily distinguish both changes without any apparent problem. For generating human faces, it is essential not to vary the wrong component. For instance, if we want the 3d-model of a person to smile, we need to change model parameters, such that mouth and eyes change in a way that human observers consider as smile. State-of-the-art models, including Neural Networks, have great difficulties doing so without changing the person properties at the same time. In other words, when current algorithms are used to perform an inter-expression change, the person also varies as observed by a human.
Before a model can be estimated, the available data has to be carefully preprocessed.
Temporal Alignment
Given 3D scans of different length, a temporal alignment is performed to compute sequences of the same length. First the expression intensity for each frame is estimated to receive a one-dimensional signal. These are then used for alignment.
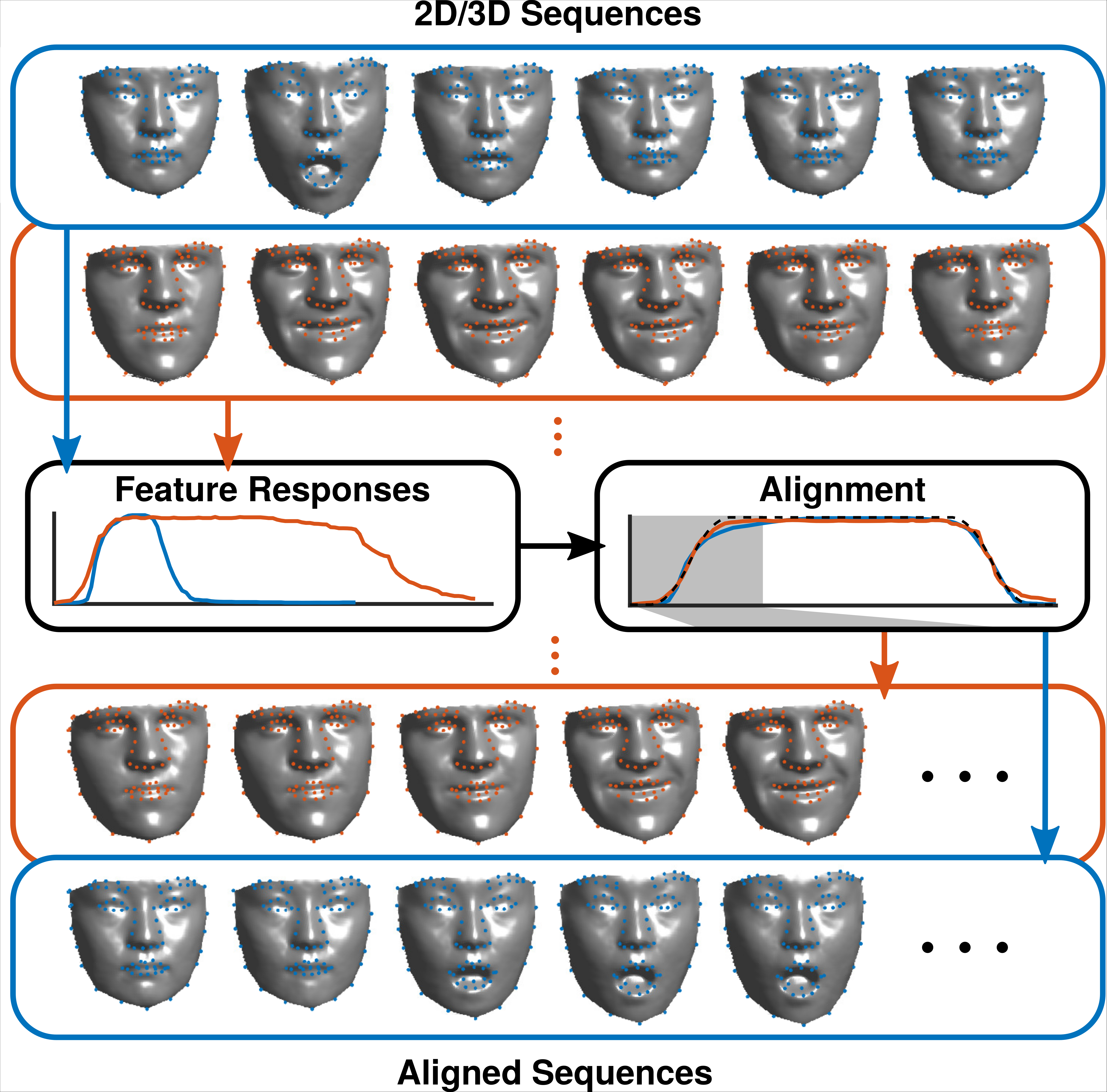
Spatial Alignment
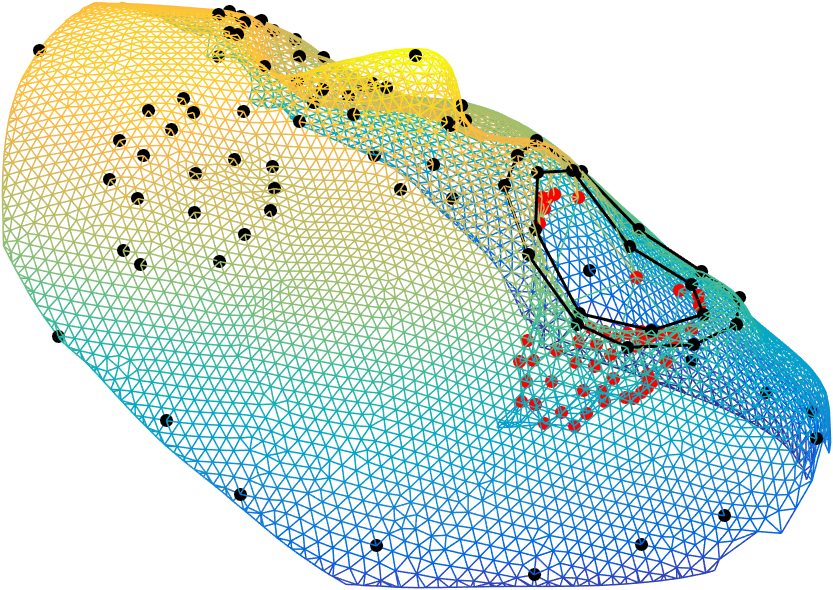
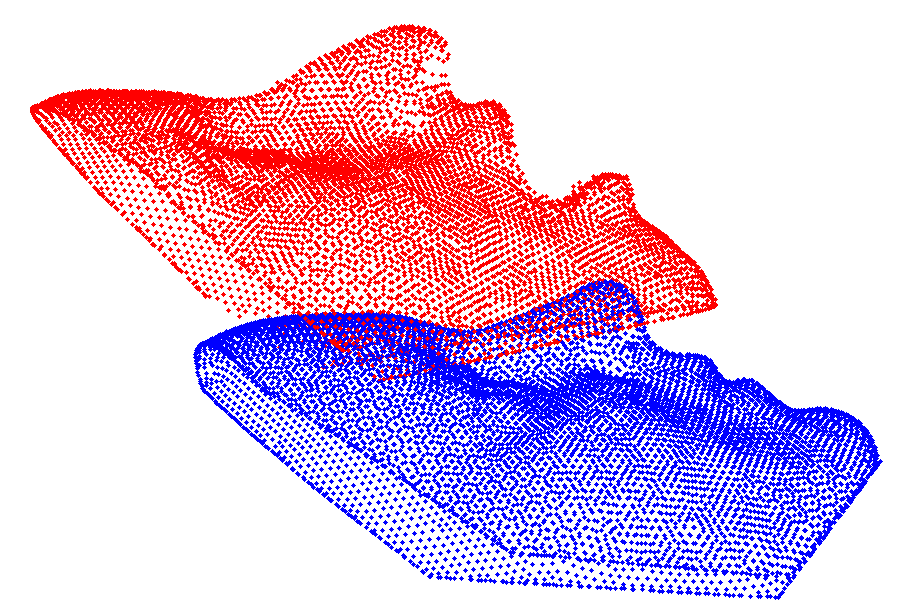
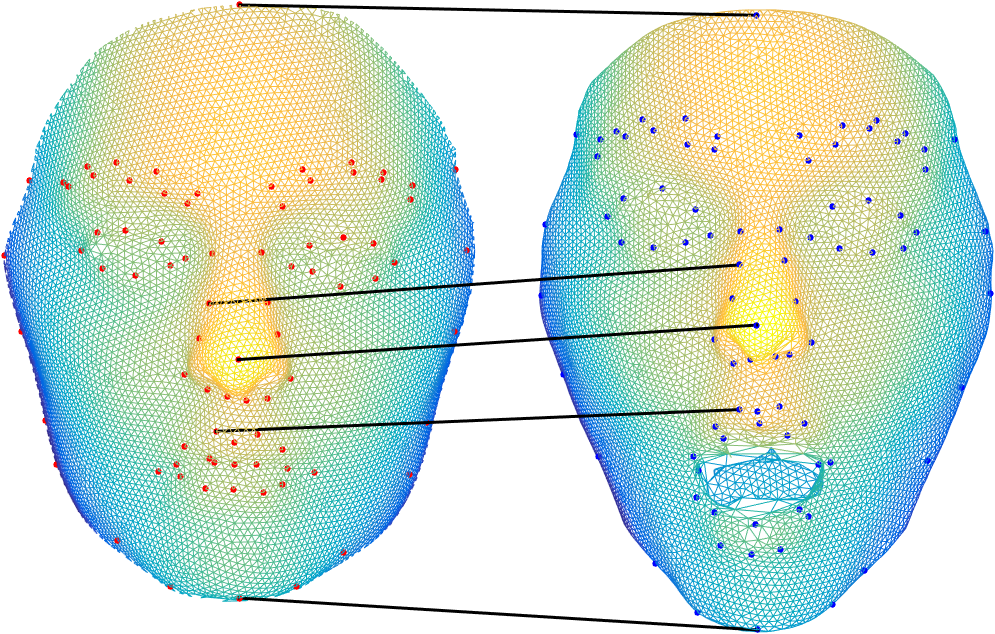
Given that 3D face scans have a different number of points, a preprocessing and spatial alignment is necessary, which includes nonrigid registration and correspondence estimation. The goal is to receive a set of 3D point clouds, which all have the same number of points and the points of all scans have a semanitcally meaningful one-to-one-correspondence.
 |
 |
 |
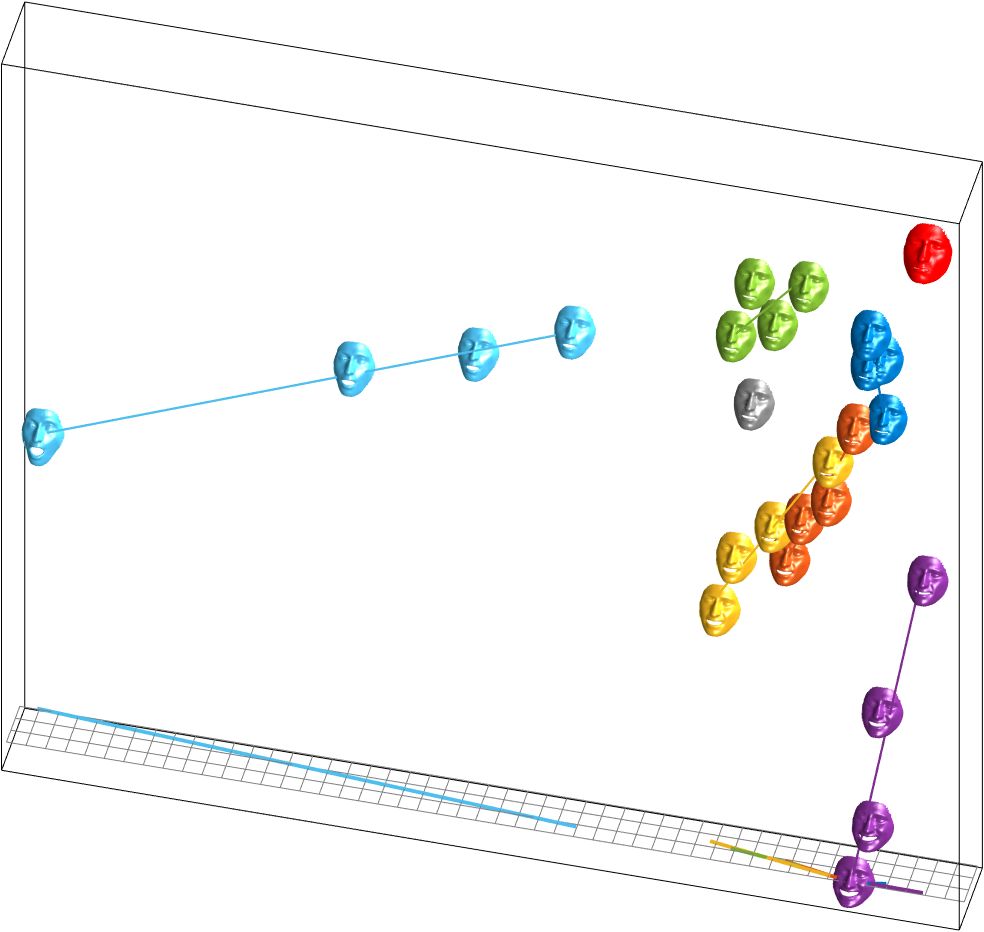
Expression Space
After factorization of the data tensor of the aligned data (left) the subspaces reveal specific structures. For the expression space (middle), it can be observed that the 25 expressions (6 emotions in 4 expression strength, and neutral) lie on a planar, star-shaped structure. If the the 4 different expression intensities (levels) of each prototypical emotion are interpolated by one line, we can estimate a new origin of the expression space on the upper right corner, depicted in red. In contrast to the neutral facial expression (gray), which lies in the middle and has an open mouth, the newly discovered facial expression (red) has a closed mouth and all facial muscles seem to be relaxed. We therefore defined the new origin of the expression space as apathy, which is not part of the database.
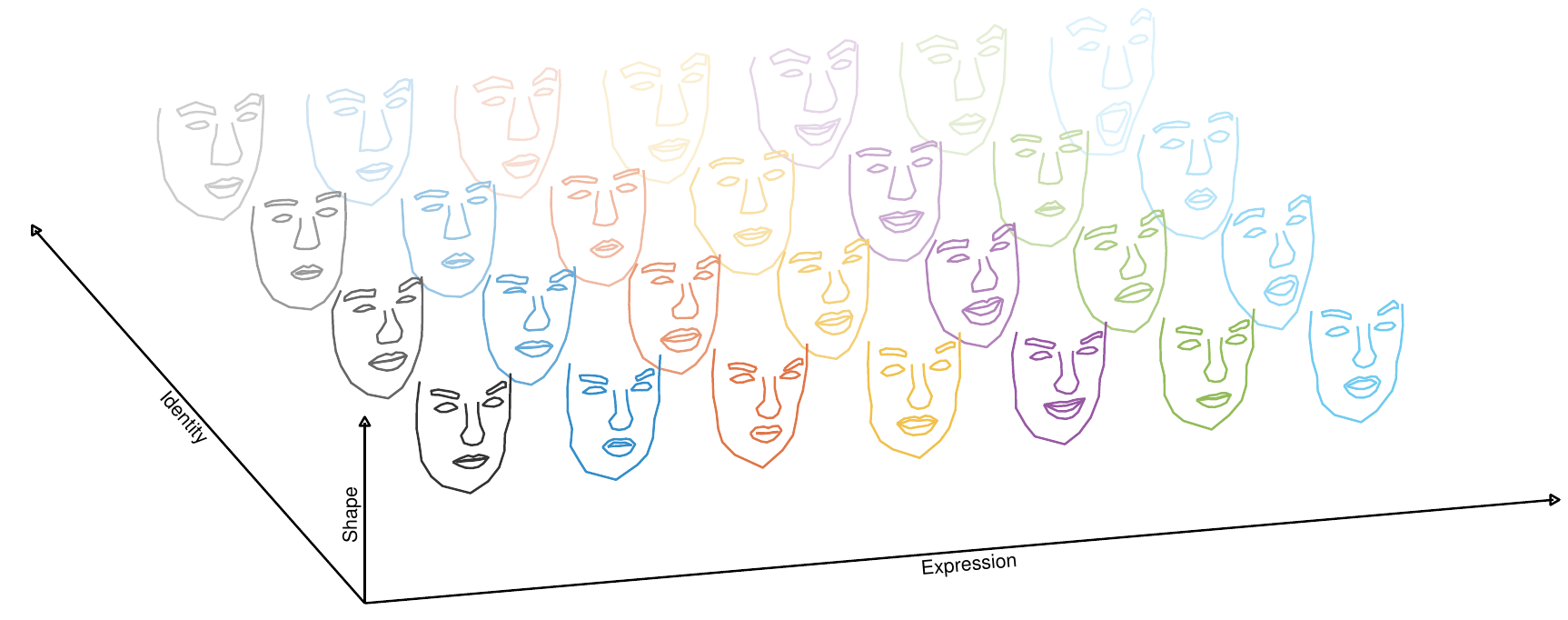 |
 |
  |
After careful preprocessing of human face scans, the aligned data is used to estimate a statistical human face model by a factorization approach. Thereby an inherent substructure in expression space is revealed. Taking use of this structure during parameter estimation procedure stabilizes the estimation scheme, where person and expression parameter are estimated after one-another.
The resulting 3D face model offers stable modification of parameters for person and expression.
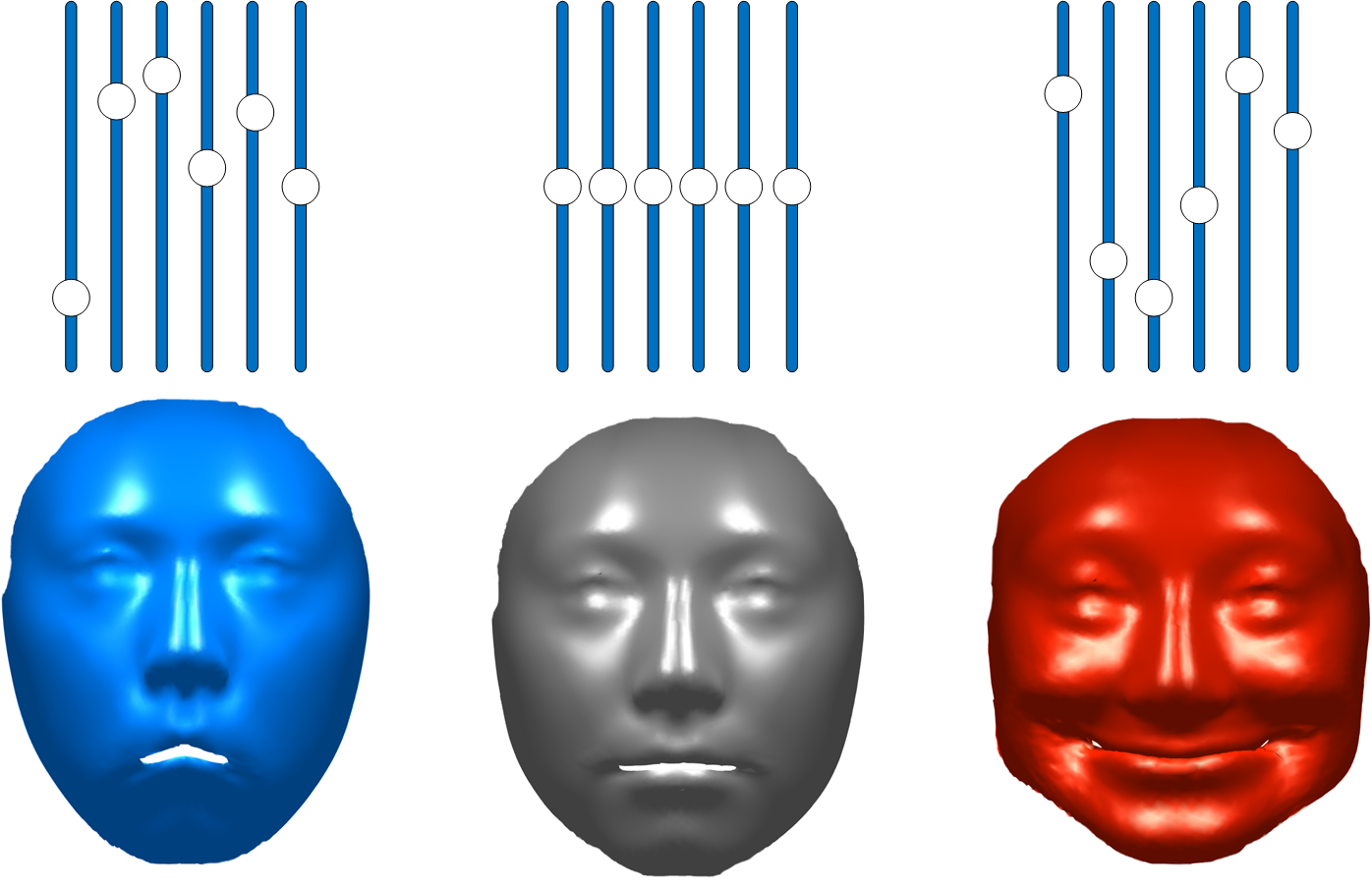
Applications
|
|
|
|
|
Reconstructed 3D face with Candide3 face model |
Reconstructed 3D face with tensor face model |
For code of this project please contact Stella Grasshof.
If you are interested in a thesis within this project, please contact Stella Graßhof or Felix Kuhnke.




