At Institut für Informationsverarbeitung (TNT) we are interested in analyzing and synthesizing the human face. Our motivation is to provide tools for efficient interpretation, evaluation and creation of facial shapes, (inter)actions and virtual faces, thereby enabling natural human-computer interaction (HCI).
We analyze different kinds of face data such as still images, videos, 3D point clouds, and others, then process and describe them with mathematical tools.
Obtaining deeper insights and understandings of underlying structures, processes, and perception, enables us to provide methods for further analysis and synthesis in various applications.
Among others our expertise within this project includes:
Considering face data can be provided as images, videos, 3D point clouds and others of single and multiple persons, the possibilities to record human faces has a large variability.
Despite their diversity the different modalities share the need of preprocessing before the data can be utilized for applications in Machine Learning or other purposes.
E.g. first steps for face scans are deletion of outlier points or inner mouth points, as shown below.
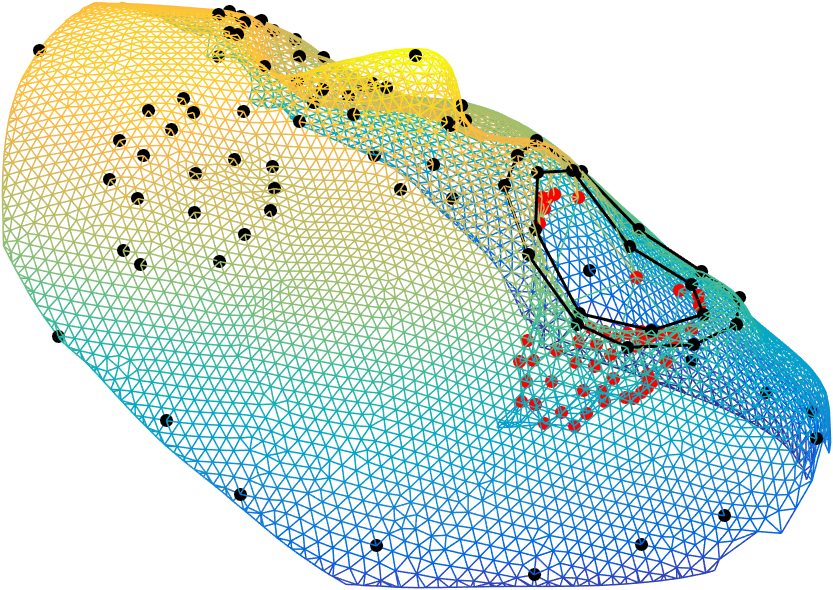
Spatial Alignment
Multiple 3D face scans differ in the number of points, and therefore need a general rigid alignment, followed by a registration and correspondence estimation procedure.
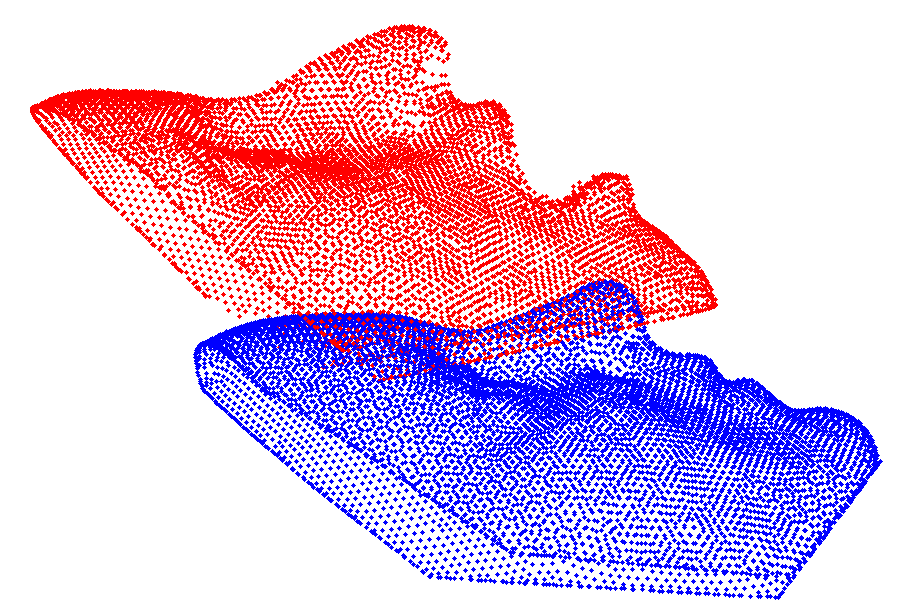 |
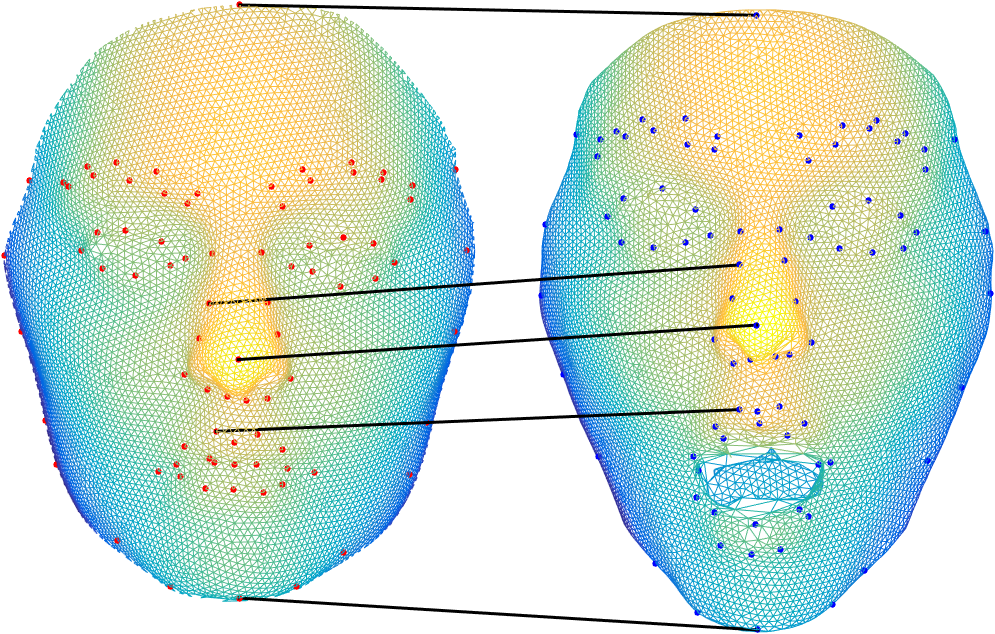 |
Temporal Alignment
Given multiple sequences of facial motion, they commonly differ in length and therefore require a temporal alignment. We offer an approach to estimate the expression intensity for each frame, and proceed to use the feature to align sequences of 3D face scans.
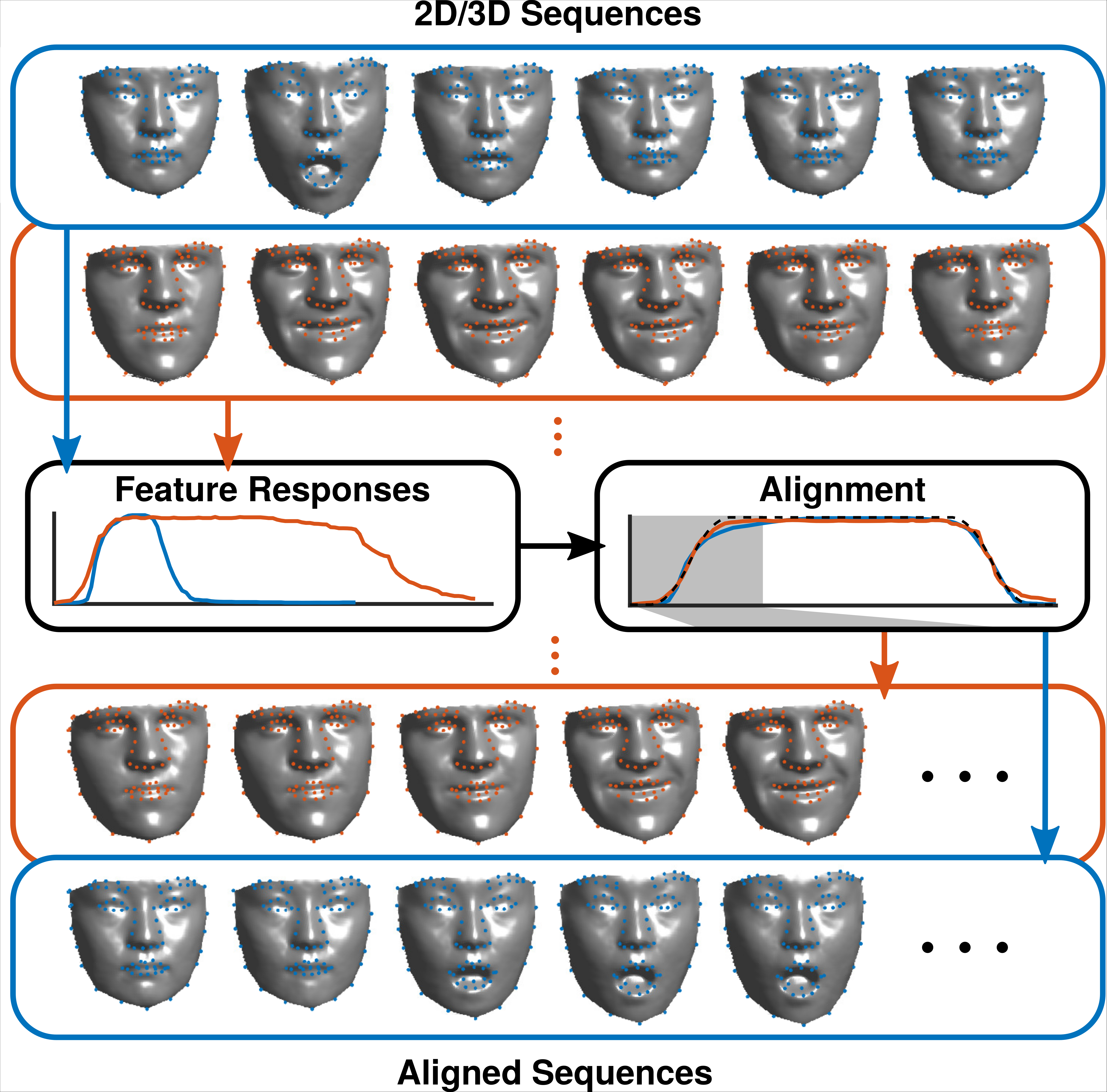
Our goal is to create a versatile 3D model for human faces with various applications.
Assuming well-prepared data, e.g. 3D face scans, a statistical face model can be estimated from the data, offering a wide range of different applications.
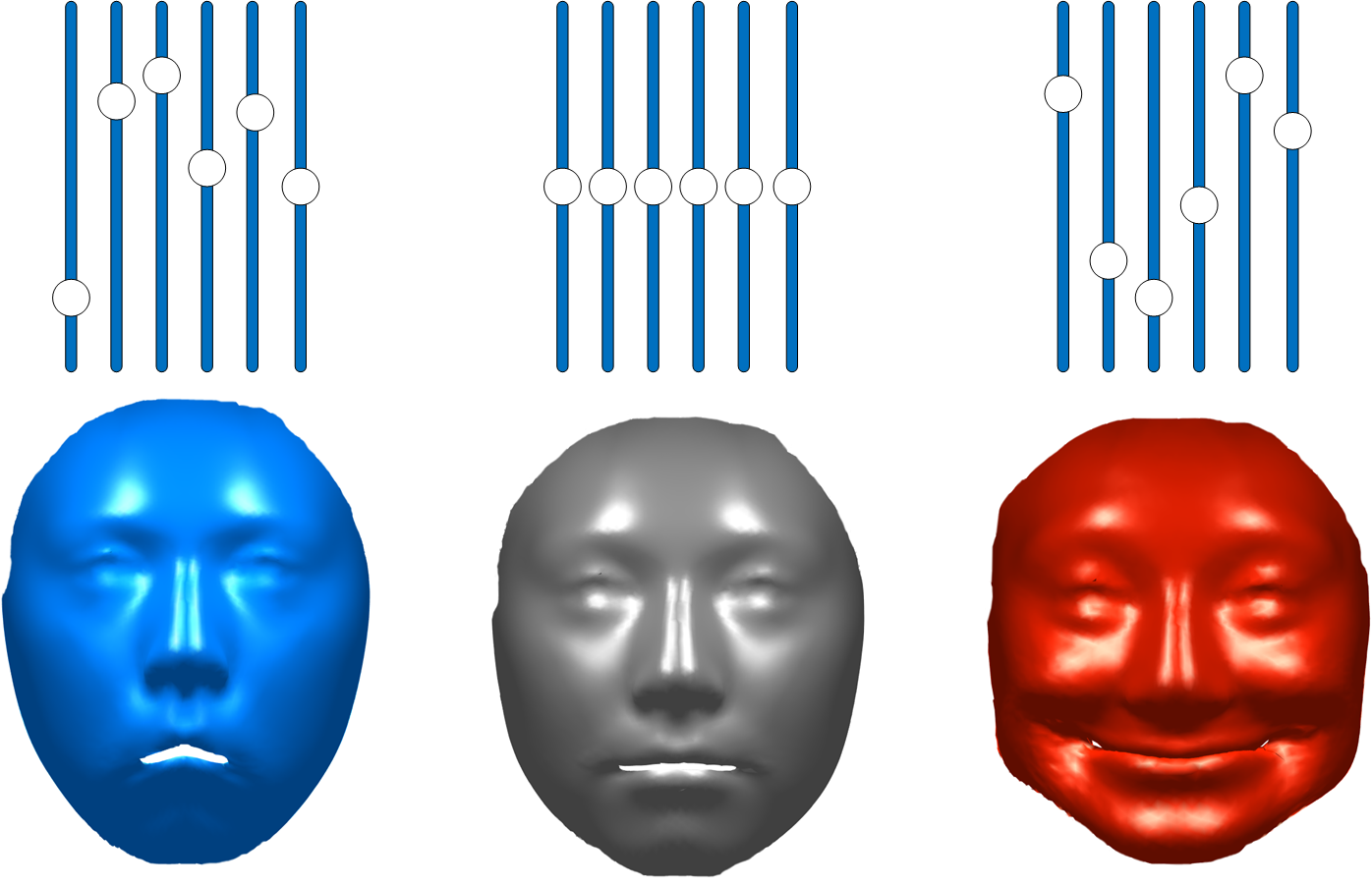
3D Face Reconstruction
Based on sparse 2D landmarks, from single or multiple images of one person, we are able to reconstruct the 3D structure of a face, and alter the expression.

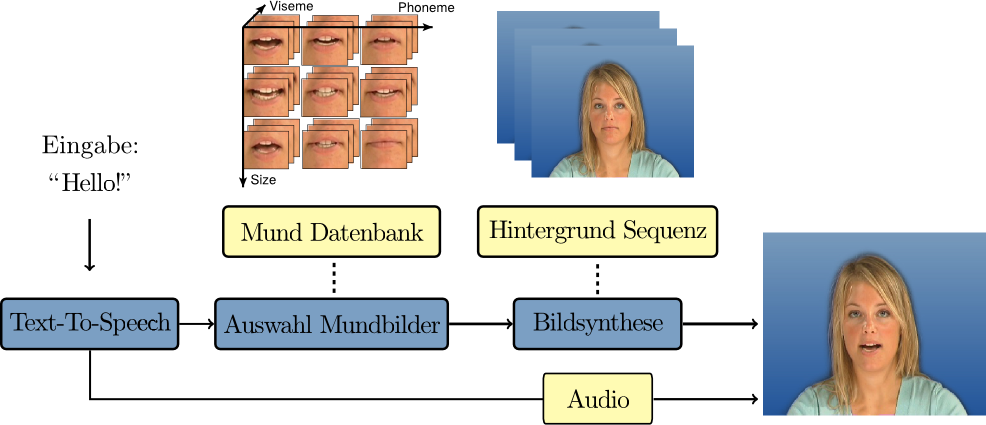
While humans are used to the application of lip-reading, we here consider the problem vice-versa: Given an audio signal, what is the most plausible visual counterpart? Based on audio input, we use synthesis of visual speech to synthesize a sequence of 3D face meshes to produce speech animations.

Talking Heads
One of our longer standing goals has been to produce Talking Heads (realistic talking virtual human faces) for Human-Computer Interaction. The major challenge is to produce visuals indistinguishable from real faces. Besides texture and geometry of the virtual head, dynamic features like linguistically correct speech animation and realistic facial animation of facial expressions are important factors. Furthermore, the behavior and animation of the virtual face needs to consider the human dialog partner.
In addition, using a talking head in a dialog based interaction requires an underlying dialog system. A dialog system will handle the content of the audible/spoken part of the interaction. It processes the users speech using techniques from text-to-speech and natural language processing and will also generate natural speech output based on natural language understanding and generation.