One of the fundamental problems in computer vision is automatic segmentation of complex content of images and videos, so called object segmentation, which is to produce a binary segmentation, separating foreground objects from their background. In video object segmentation, one has to automatically segment the objects in an unannotated video. This is a challenging task, as local image measurements often provide only a weak cue. Object appearance may significantly change over the video frames due to changes in the camera viewpoint, scene illumination or object deformation. Most approaches are to extend single image segmentation techniques to multiple frames, exploiting the fact that there is redundancy along the time axis and that the motion field is smooth. While this can be attempted by analyzing individual image frames independently, video provides rich additional cues beyond a single image. These cues include object motion, temporal continuity, and long-range temporal object interactions, etc.
In this project, we aim to obtain a spatio-temporal foreground segmentation of a video that respects object boundaries, and at the same time temporally associates object pixels whenever they appear in the video. The problem will be formulated as inference in a conditional random field (CRF). We make use of point trajectories, which have rich grouping information in their motion differences. The CRF contains binary variables representing the class labels of image pixels as well as binary variables indicating the correctness of trajectory clustering.
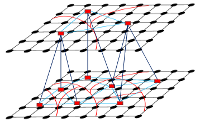
The problem of video segmentation is formulated as inference in a CRF. The challenge here is to model object labeling and trajectory clustering in a unified probabilistic framework to facilitate video segmentation. Therefore, joint object and trajectory segmentation will be formulated as a pixel and trajectory labeling problem of assigning each pixel and trajectory with either foreground or background. The random field contains binary variables representing the class labels of image pixels as well as binary variables indicating the correctness of trajectory clustering. This model combines different views on the video data by specific potentials and the trajectory labeling accounting for long range motion cues, as illustrated in the above figure. Object and trajectory will be optimized in the joint space via the space-time CRF.