Video coding has been playing an important role in the world of communication and multimedia systems since the 1990s where bandwith is still a valuable commodity. Video coding techniques offer the possibility of coding video at the lowest possible bit rate while maintaining a certain level of video quality. The lastest video coding standard, High Efficieny Video Coding (HEVC), has the capability of doubling the data compression ratio compared to H.264/MPEG-4 AVC at the same level of video quality. The current standard consists of major cornerstones such as intra-frame prediction, inter-frame prediction, scaling, transform as well as scalar quantization.
However, an increased diversity of services and the growing need of applications based on videos of high resolutions (e.g. 4k x 2k, 8k x 4k) leaves still enough space to be improved. At Institut für Informationsverarbeitung (TNT), a variety of aspects of video coding has been studied to further improve the current HEVC standard, which are listed below.
The prediction tools which led to the prosperous application of modern video coding standards can be roughly distinguished into inter and intra coding tools. While intra coding solely relies on information which is contained in the current picture, inter coding uses the redundancy between different pictures to further increase the coding efficiency. Therefore, in general, intra coding requires considerably higher bit rates than inter coding to achieve the same visual quality for typical video signals.
Nevertheless, intra coding is an essential part of all video coding systems: it is required if new content appears in a sequence, to start a video transmission, for random access into ongoing transmissions and for error concealment. In this project, we aim at increasing the coding efficiency for intra prediction. Additionally, we combine contour driven technologies with video coding technologies to further improve our prediction.
The human visual system (HVS) automatically filters relevant and irrelevant information. To construct visually identical images for a viewer, only the relevant information needs to be shown to them. As the relevant information is only a small part of the original image, video coding can highly profit from modeling the HVS. We develop an algorithm where a large region of similar texture (e.g. an homogenously textured wall) is represented by a small patch extracted from that region. A region perceptually similar to the original can be reconstructed from this small patch. Obviously, only coding a small patch instead of the whole region results in high bitrate savings.
The superior coding efficiency of HEVC and its extensions is achieved at the expense of very complex encoders. It was analyzed that HEVC encoders are several times more complex than AVC encoders. One main complexity driver for HEVC encoders is the comprehensive rate-distortion (RD) optimization which is indispensable to fully exploit all benefits of the HEVC standard. A major disadvantage of the RD optimization is that encoders which cannot afford a comprehensive RD optimization will likely not accomplish the optimal coding efficiency. The RD optimization consists in the evaluation of all combination possibilities (coding modes, parameter for these coding modes, partitioning, etc.) and the selection of the combination with the smallest RD costs. In case of the intra prediction, the RD optimization determines the intra prediction mode. Specifically, for HEVC, there are 33 angular intra prediction modes, the DC mode and the planar mode.
Therefore, to overcome the described disadvantage, we aim at avoiding the RD optimization complexity for the intra prediction mode decision. Considering that the intra prediction mode decision can be formulated as a classification problem with the different intra prediction modes forming the classes, we suggest machine learning approaches as solution. Deep learning is a very active topic in the machine learning community. It is evident that deep learning approaches provide superior results for classification problems by utilizing deep convolutional neural networks (CNNs). For this reason, we use CNNs for the intra prediction mode decision.
The general motion compensation uses previously coded blocks to predict the content of current block, in order to reduce the bit rate by coding only the displacement vector and the difference instead of the original block content. The prediction accuracy, however, is decreased by varying motion blur, which accompanies objects in acceleration.
In order to compensate the inaccuracy brought by generation motion compensation, the characteristic of motion blur is studied and several approaches based on reference frame filtering have been considered and attempted. The approaches are referred to as motion blur compensation methods. Current approaches are aiming at the the case of single layer coding and avoids the additional signaling of the filter choice or the filter coeffcients. An example is shown below in Fig 1.
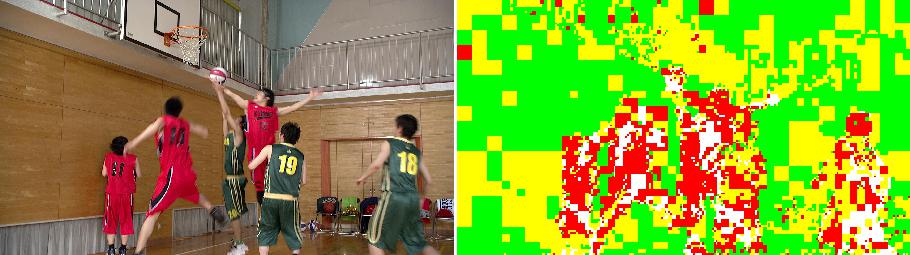
Figure 1: Prediction mode distribution. Red: Blur, Green: Skip , Yellow: Inter and White: Intra.
Applications like remote computing and wireless displays together with the growing usage of mobile devices (e.g. smartphones) have led to new scenarios how computers are used. In these scenarios the output is displayed on a different device (e.g. on a tablet computer) than the program execution device (e.g. a server in the cloud). For this purpose, the program output needs to be coded and transmitted from the execution device to the display device. Commonly, the coding of computer generated video signals is referred to as screen content coding.
A screen content coding extension for the state-of-the-art video coding standard HEVC was developed by the Joint Collaborative Team on Video Coding (JCT-VC). New coding tools, which address several typical characteristics of screen content (e.g. no noise, small number of different colors, RGB source material), were included in this extension. However, none of the new coding tools addresses static content.
Therefore, taking into account that the absence of temporal changes is very common for screen content videos, we propose coding tools specifically addressing this kind of content. This coding mode, which we refer to as copy mode, is based on the direct copy of the collocated block from the reference frame. Additionally, considering real time applications, the copy mode is enhanced with several encoder optimizations to enable the fast encoding of static content.